Tuva EMPI Overview
What is an EMPI software system?
Any organization receiving healthcare data from more than one source (e.g., medical records, medical claims, FHIR feeds, ADT messages, lab data, etc.) faces a common problem: they need to accurately identify and link patient records across multiple data sources.
Imagine a patient named John Doe visits:
- A hospital that uses Epic,
- A specialist using Cerner,
- And a clinic using Athenahealth.
Each system may create a new record for John, potentially with variations (e.g., "J. Doe" or "Johnny D."). An EMPI system uses matching algorithms to link all these records together and assign them to the same enterprise-wide ID. Doing this is essential to support high quality analytics and reporting across multiple data sets and to support care coordination by accurately identifying unique patient identities.
What is Tuva EMPI?
Tuva EMPI is an open-source enterprise master patient index (EMPI) software system. Any organization is free to view, use, modify, and distribute the code base for Tuva EMPI.
An EMPI software system that fully solves the problem of patient matching needs to integrate with an organization's data pipelines to:
- Ingest individual patient records and their demographic data from multiple data sources.
- Run a patient-matching algorithm that determines whether any given pair of records represents the same person.
- Group all records that are linked to each other into a single person identity and assign them a unique universal ID.
- Provide a user interface for users to review (and potentially edit) matches.
- Integrate all assigned unique universal IDs back into the data model used for downstream applications.
Tuva EMPI is designed to do all of these things and seamlessly integrate with the Tuva Data Model. Here is a high-level overview of the data flow when Tuva EMPI is set up for doing patient matching and integrating with the Tuva Data Model:
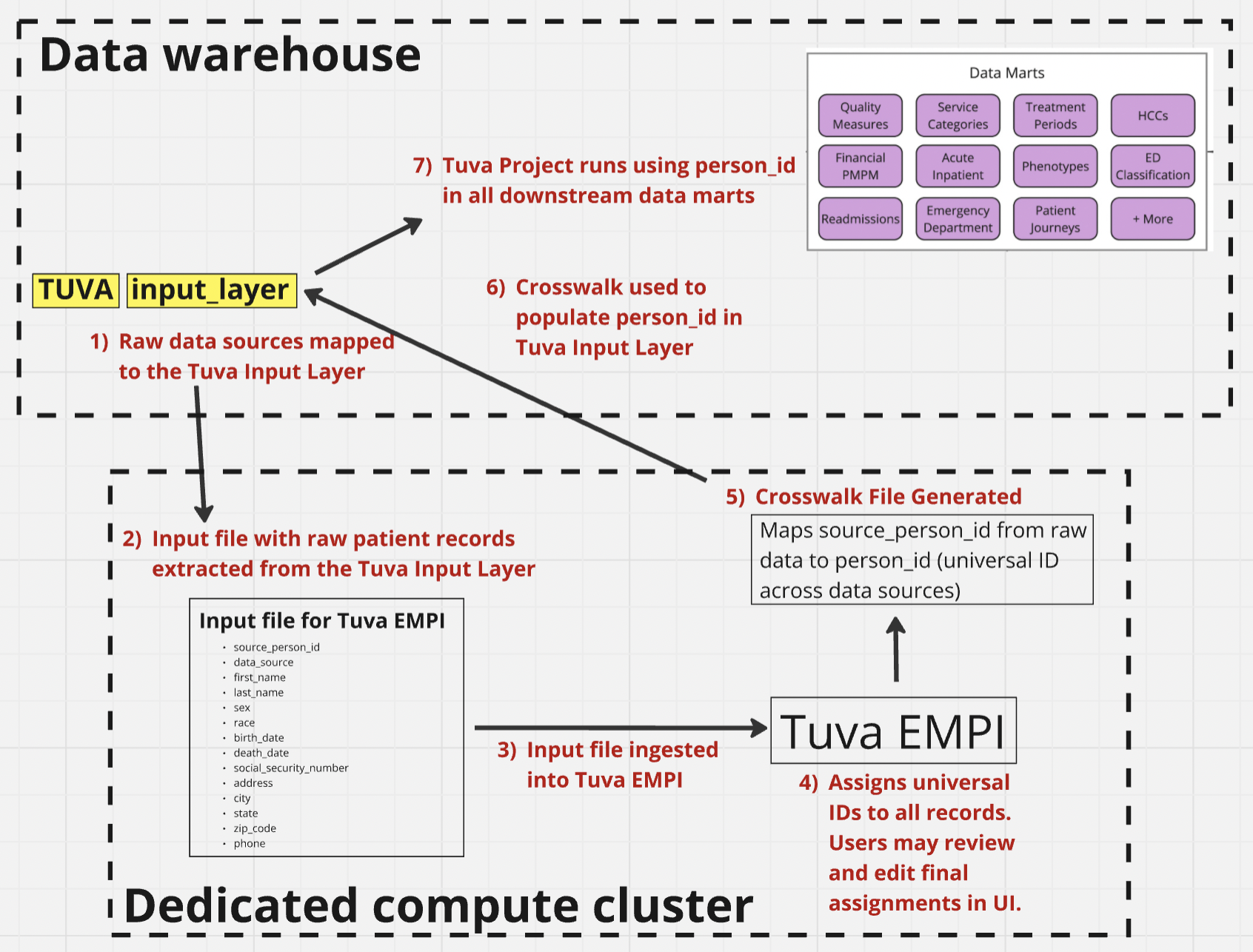
To run the Tuva Project, it is necessary to map your raw healthcare
data sources into
the Tuva Input Layer
by creating dbt models in your dbt project for each relevant input layer table.
Once this is done, the Tuva package
can be imported and ran to populate
the entire Tuva Data Model with your healthcare data.
For users setting up Tuva EMPI, the data flow described in the picture above
must be set up to populate Tuva's universal patient identifiers
(person_id) in the Tuva Input Layer before running the Tuva Project.
Here's a breakdown of the basic steps in this data flow:
1) Raw data sources mapped to the Tuva Input Layer
This is the first step anyone would do when running the Tuva Data Model.
This is typically done by creating dbt models within your dbt project
for each relevant input layer table. The Tuva Project runs by referencing those
models using the dbt ref() function. When creating dbt models for each
Tuva Input Layer table, a user would populate the member_id field
(for claims input layer tables)
or the patient_id field (for clinical input layer tables)
with the patient identifiers present in their
raw data.
The person_id field in the Tuva Input Layer tables is initially left null,
and will be later populated with the universal IDs generated by Tuva EMPI.
2) Input file with raw patient records extracted from the Tuva Input Layer
Next we need to extract all distinct patient records from the Tuva Input Layer. A raw patient record is a vector containing the following fields:
- source_person_id
- data_source
- first_name
- last_name
- sex
- race
- birth_date
- death_date
- social_security_number
- address
- city
- state
- zip_code
- phone
Note that the same person can have multiple records in the dataset with
different values for key demographic fields. For example, John Doe can
have an eligibility span between 2024-06-01 and 2024-06-30 with one address,
and a different eligibility span from 2024-07-01 and 2024-12-31 with a
different address. Each of those forms a distinct patient record. It will
be the job of Tuva EMPI to determine that those records are associated
with the same person and to assign them the same person_id.
Patient records are extracted from the input_layer.eligibility table for
claims datasets, and from the input_layer.patient table for clinical
datasets.
The following query produces the set of all distinct patient records from the Tuva Input Layer:
select distinct
member_id as source_person_id,
data_source,
first_name,
last_name,
gender as sex,
race,
birth_date,
death_date,
social_security_number,
address,
city,
state,
zip_code,
phone
from tuva.input_layer.eligibility
union all
select distinct
patient_id as source_person_id,
data_source,
first_name,
last_name,
sex,
race,
birth_date,
death_date,
social_security_number,
address,
city,
state,
zip_code,
phone
from customer_tuva.input_layer.patient
When setting up Tuva EMPI, we at Tuva Health typically extract this file from the input layer with a Prefect flow, but users may choose to do this with their prefered ETL tool.
3) Input file ingested into Tuva EMPI
The file extracted from the Tuva Input Layer containing all raw patient records is now ingested into Tuva EMPI. We at Tuva do this using a Prefect flow, but again, users may choose to do this with their prefered ETL tool.
4) Tuva EMPI assigns universal IDs to all records
Tuva EMPI automatically groups all patient records that correspond
to the same person by assigning them the same person_id.
These assignments that happen automatically are called auto-matches.
Users may review existing matches in the UI of the Tuva EMPI web application.
Users may also do manual matches by editing existing matches or manually splitting
or linking patients.
5) Crosswalk file generate
When matches are finilized for a given batch of data, Tuva EMPI exports a crosswalk file that links source patient identifiers (member_id for claims data and patient_id in clinical data) to the newly generated universal IDs (person_id).
6) Crosswalk file is used to populate person_id in the Tuva Input Layer
The crosswalk file is used to populate the universal patient ID generated by
Tuva EMPI (person_id) in the Tuva Input Layer.
When setting up Tuva EMPI, we at Tuva Health typically set up a data
pipeline to populate person_id in
the Tuva Input Layer with a Prefect flow, but users may choose to
do this with their prefered ETL tool.
7) The Tuva Project runs using the universal person_id in all downstream data marts
Now that the universal patient ID (person_id) is populated in the Tuva Input Layer,
the Tuva Project may run, automatically populating the entire Tuva Data Model with
the universal person_id field being used as a unique patient identifier across
all data sources in all downstream data marts.